Data! Data! Data! It is the reason we do science, the carrot at the end of the cart of discovery, the pièce de resistance of our existence… OK, maybe not quite that far.
No matter its rank, we spend incredible amounts of time reviewing previous data (published and our own).
From meticulously designing studies to avoid pursuing false leads or duplicating data to collecting, analyzing, and conferring with colleagues for their impressions of ourdata (often receiving very… constructive feedback), we likely re-analyze the data many times.
I don’t know about you, but throughout this process there are 2 potential scenarios that fill every cell in my body with dread:
1. Oh No! What if I, or someone else, accidentally changed the dataand I don’t know it’s been changed– so my results are no longer valid?!
2. I need to look at the results from the study I did last year. So… Where did I put that data?
One of the advantages of our uber-connected world is data sharing – sending it hither and thither for bioinformatic analysis, collaboration, peer review, director approval, dissemination, and implementation. The loss of data integrity is a very real possibility during any of these processes – I’m looking at you, shared spreadsheets and documents.
Digital transformation to cloud-based LIMS is a multi-million-dollar industry because it works. An integrated cloud based end-to-end solutionstreamlines and expedites the drug discovery process, reduces cost, saves time, and gets drugs to market faster.
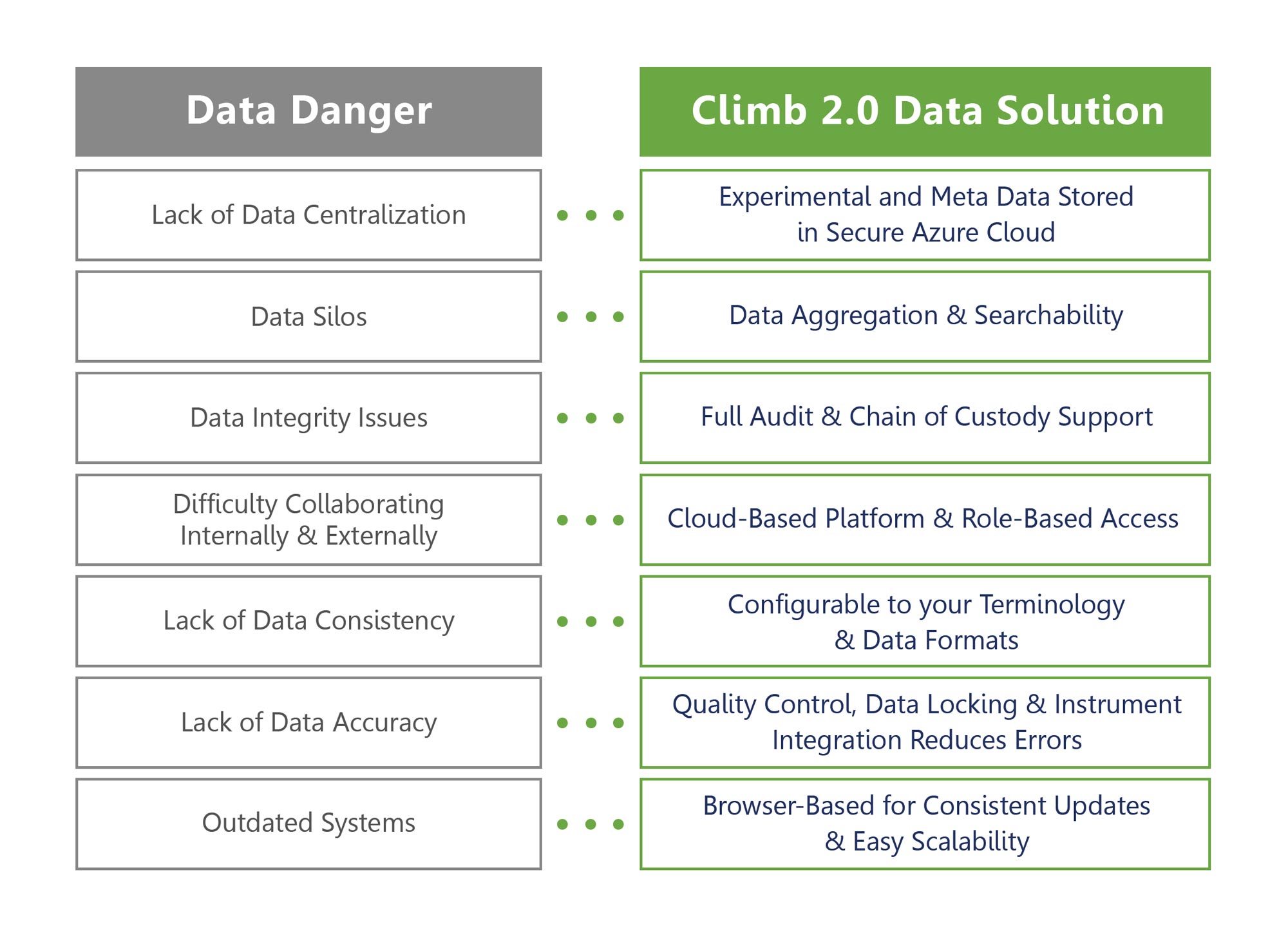
Below we outline how Climb 2.0 addresses Data Danger.
Stay up to date on our latest articles, delivered directly to your inbox.
About Our Blog
Support researchers on their quest to adopt best practices in the in vivo lab and stay up-to-date on the latest trends and insights from the experts at RockStep Solutions.
Organize. Automate. Accelerate.
Modernize in vivo Research
Discover how Climb can help revolutionize your in vivo workflow.